Foundations of Python Network Programming - 读书笔记系列(2) - Web Services
本文共 5547 字,大约阅读时间需要 18 分钟。
Web Client Access
HTTP(Hypertext Transfer Prototol)协议是如今使用最广的协议之一。Python中通常使用urllib2模块来实现HTTP协议。urllib和urllib2的区别?urllib2更据扩展性,同时和urllib一样具备了基本的功能。而urllib提供了较多的一些实用的功能。
1. Fetching Web Pages
 import sys, urllib2req = urllib2.Request(sys.argv[ 1 ])fd = urllib2.urlopen(req) print " Retrieved " , fd.geturl()info = fd.info() for key, value in info.items(): print " %s = %s " % (key, value)
import sys, urllib2req = urllib2.Request(sys.argv[ 1 ])fd = urllib2.urlopen(req) print " Retrieved " , fd.geturl()info = fd.info() for key, value in info.items(): print " %s = %s " % (key, value) urllib2.urlopen()返回的是一个File-like对象,因此可以调用read()方法,比如:
import sys, urllib2req = urllib2.Request(sys.argv[ 1 ])fd = urllib2.urlopen(req) while 1 : data = fd.read( 1024 ) if not len(data): break sys.stdout.write(data) 2. Authenticating
通常,某些网页需要HTTP安全性验证才能访问(SSL),比如需要提供用户名和密码的信息。如果我们没有提供不要的信息去访问一个需要安全性验证的网页,将会返回一个HTTP401(Authorization Required),urllib2模块能够处理这种情况,看下面的例子: import sys, urllib2, getpass class TerminalPassword(urllib2.HTTPPasswordMgr): def find_user_password(self, realm, authuri): retval = urllib2.HTTPPasswordMgr.find_user_password(self, realm, authuri) if retval[0] == None and retval[ 1 ] == None: # Did not find it in stored values; prompt user. sys.stdout.write( " Login required for %s at %s\n " % \ (realm, authuri)) sys.stdout.write( " Username: " ) username = sys.stdin.readline().rstrip() password = getpass.getpass().rstrip() return (username, password) else : return retvalreq = urllib2.Request(sys.argv[ 1 ])opener = urllib2.build_opener(urllib2.HTTPBasicAuthHandler(TerminalPassword()))fd = opener.open(req) print " Retrieved " , fd.geturl()info = fd.info() for key, value in info.items(): print " %s = %s " % (key, value) 仔细分析一下上面的代码,第一步还是一样调用了Request()方法,第二步使用了urlib2.build_opener()方法创建一个opener,里面的参数是类似委托类型,当网页需要安全性验证时,HTTPBasicAuthHandler将会自动调用委托的方法TerminalPassword,而这个TerminalPassword是一个继承自urllib2.HTTPPasswordMgr的类,用于在需要用户名和密码时提供相应的信息。其实,在我们的第一个例子中(不需要安全性验证的例子),build_opener()在urlopen()的内部自动被调用了,传的参数为空,因为网页不需要安全性验证。
3. Submitting Form Data -- Get
提交表单数据其实有很多种,本书提到了是两种:Get和Post,其实还有比如:Put方式(不知道Python里有没有提供)。先来看Get方式,Get方式是直接把要提交的数据放在URL里的,每个参数之间用&号隔开。看下面的代码: import sys, urllib2, urllib def addGETdata(url, data): """ Adds data to url. Data should be a list or tuple consisting of 2-item lists or tuples of the form: (key, value). Items that have no key should have key set to None. A given key may occur more than once. """ return url + ' ? ' + urllib.urlencode(data)zipcode = sys.argv[ 1 ]url = addGETdata( ' http://www.wunderground.com/cgi-bin/findweather/getForecast ' , [( ' query ' , zipcode)]) print " Using URL " , urlreq = urllib2.Request(url)fd = urllib2.urlopen(req) while 1 : data = fd.read( 1024 ) if not len(data): break sys.stdout.write(data) 4. Submitting From Data -- Post
Post方式是把要提交的数据单独放在一个地方而不是简单的放在URL中,主要用于发送一些比较大的数据。使用起来其实也很简单,如下: import sys, urllib2, urllibzipcode = sys.argv[ 1 ]url = ' http://www.wunderground.com/cgi-bin/findweather/getForecast ' data = urllib.urlencode([( ' query ' , zipcode)])req = urllib2.Request(url)fd = urllib2.urlopen(req, data) while 1 : data = fd.read( 1024 ) if not len(data): break sys.stdout.write(data) username = abc & search = whoareyou 5. Catching Connection Errors
连接一个地址时,假如主机不存在,域名错误等等,会返回一些错误的信息,比如:404(File Not Found)。而urllib2.URLError可以捕捉连接时的任何异常。然后,HTTP的一些异常信息通常伴随着一些描述性的文档,当我们只是要捕捉这样的异常,同时获取异常的内部信息时,可以使用urllib2.HTTPError来捕获,urllib2.HTTPError是urllib2.URLError的子类,它是一个file-like对象,因此可以直接用read()方法读取内部信息。下面的例子: import sys, urllib2req = urllib2.Request(sys.argv[ 1 ]) try : fd = urllib2.urlopen(req) except urllib2.HTTPError, e: print " Error retrieving data: " , e print " Server errror document follows:\n " print e.read() sys.exit( 1 ) except urllib2.URLError, e: print " Error retrieving data: " , e sys.exit( 2 ) print " Retrieved " , fd.geturl()info = fd.info() for key, value in info.items(): print " %s = %s " % (key, value) 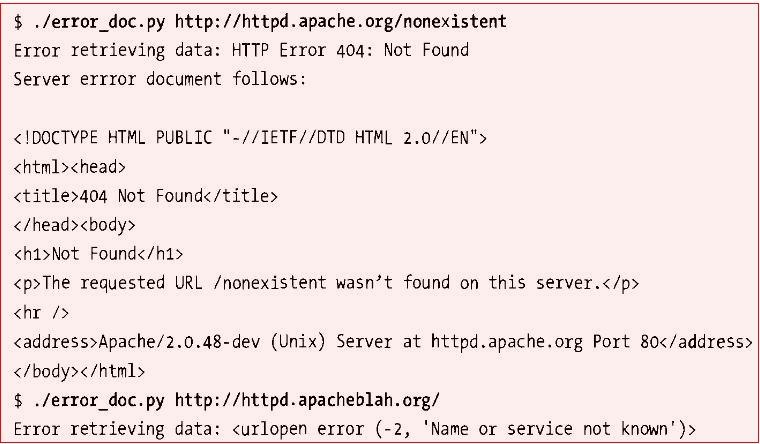
6. Cathing Data Errors
前面是捕捉了连接时的异常,同样,在读数据或写数据时,也会发生异常。有两种情况:一是当使用read()时,连接出现异常(communication error),会抛出socket.error,这时我们捕获这个异常就可以了。二是读取的文件读到一半意外被中断,比如服务器的某个程序崩溃了,这时,连接会被正常的关闭,你接受不到任何异常的信息。这时,你就必须从header里找Content-Length,然后和自己接收的数据大小进行比较。(Content-Length在其他非HTTP协议中通常是没有的) import sys, urllib2, socketreq = urllib2.Request(sys.argv[ 1 ]) try : fd = urllib2.urlopen(req) except urllib2.HTTPError, e: print " Error retrieving data: " , e print " Server errror document follows:\n " print e.read() sys.exit( 1 ) except urllib2.URLError, e: print " Error retrieving data: " , e sys.exit( 2 ) print " Retrieved " , fd.geturl()bytesread = 0 while 1 : try : data = fd.read( 1024 ) except socket.error, e: print " Error reading data: " , e sys.exit( 3 ) if not len(data): break bytesread += len(data) sys.stdout.write(data) if fd.info().has_key( ' Content-Length ' ) and \ long(fd.info()[ ' Content-Length ' ]) != long(bytesread): print " Expected a document of size %d, but read %d bytes " % \ (long(fd.info()[ ' Content-Length ' ]), bytesread) sys.exit( 4 ) urllib2模块不仅仅支持HTTP协议,同样支持其他非HTTP协议,比如FTP。不同的是,比如FTP协议你不会在有header的信息,因此你当你调用info()函数时会出错的。不过通常情况下,使用urllib2来进行其他非HTTP协议也是非常方便的,基本上不需要再额外做什么,比如最前面第二个例子,我们讲传入的参数设置为FTP地址,同样使用。
import sys, urllib2req = urllib2.Request(sys.argv[ 1 ])fd = urllib2.urlopen(req) while 1 : data = fd.read( 1024 ) if not len(data): break sys.stdout.write(data) 
本文转自CoderZh博客园博客,原文链接:http://www.cnblogs.com/coderzh/archive/2008/06/23/1228429.html,如需转载请自行联系原作者
你可能感兴趣的文章
DIV+CSS命名规范有助于SEO
查看>>
web项目buildPath与lib的区别
查看>>
我的友情链接
查看>>
ifconfig:command not found的解决方法
查看>>
计算机是怎么存储数字的
查看>>
Codeforces Round #369 (Div. 2) A. Bus to Udayland 水题
查看>>
adb上使用cp/mv命令的替代方法(failed on '***' - Cross-device link解决方法)
查看>>
C++标准库简介、与STL的关系。
查看>>
Spring Boot 3 Hibernate
查看>>
查询EBS请求日志的位置和名称
查看>>
大型机、小型机、x86服务器的区别
查看>>
J2EE十三个规范小结
查看>>
算法(第四版)C#题解——2.1
查看>>
网关支付、银联代扣通道、快捷支付、银行卡支付分别是怎么样进行支付的?...
查看>>
大数据开发实战:Stream SQL实时开发一
查看>>
C++返回引用的函数例程
查看>>
dll 问题 (转)
查看>>
REST API用得也痛苦
查看>>
test for windows live writer plugins
查看>>
Tiny210 U-BOOT(二)----配置时钟频率基本原理
查看>>